

The Causes of Unreliable Software
The Causes of Unreliable Software
Organizational complexity is the best predictor of bugs in a software module.

This is the latest issue of my newsletter. Each week I cover research, opinion, or practice in the field of developer productivity and experience.
This week I read The Influence of Organizational Structure On Software Quality, a Microsoft-based case study from 2008 that has been since replicated. This study investigated the causes of unreliable software, and whether organizational complexity is among those.
My summary of the paper
Before this paper, numerous studies had explored the relationship between factors like code complexity, code dependencies, and code coverage on software quality. There had also been literature, like The Mythical Man Month, stating that quality is strongly affected by organizational structure. However, there was no evidence to substantiate that claim as research had not yet explored the relationship between organizational complexity and software quality.
The researchers identified this as a blind spot: “these [previous studies] ignore one of the most influential factors in software development, specifically ‘people and organizational structure.’” This was the motivation for their study, which was conducted at Microsoft in two parts:
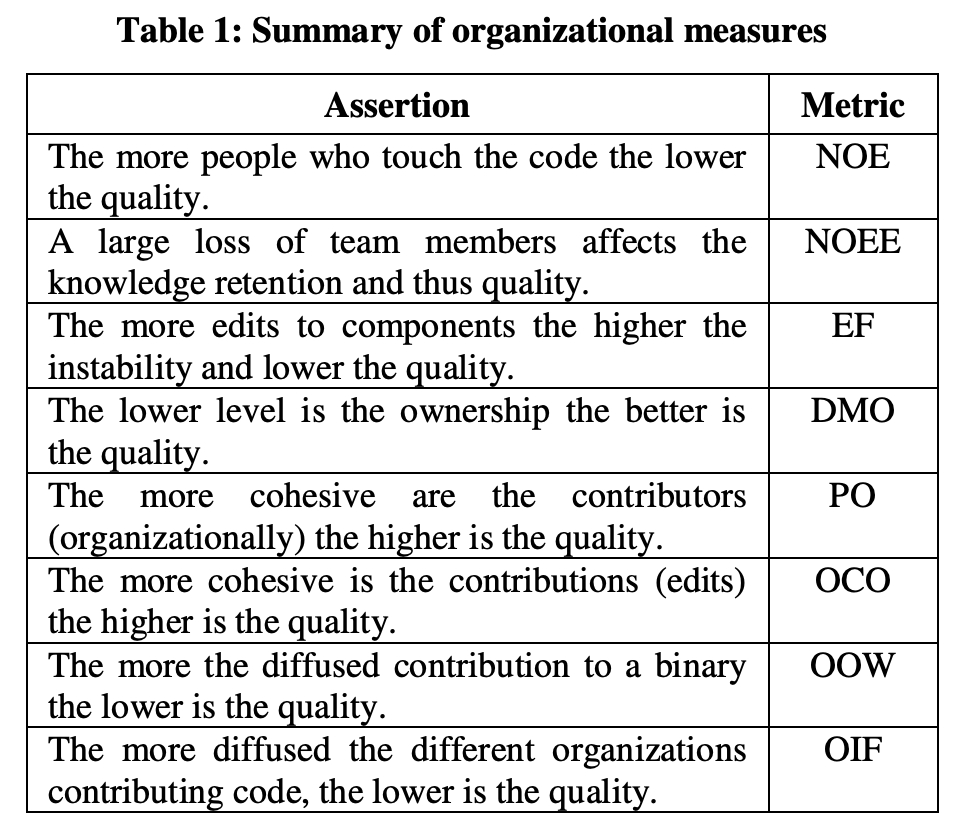
First, the researchers proposed a set of eight measures that quantify organizational complexity.
Those measures were then used to quantify the effect that an organization’s structure has on software quality. This new model was compared to other pre-existing models for predicting software bugs such as code complexity, code dependencies, code churn, code coverage, and pre-release defects, to compare which factors are better predictors of code quality.
Measures used for quantifying organizational complexity
Organizational metrics were developed and refined using the Goal-Question-Metric approach, an approach that was outlined in an earlier paper. The eight measures the researchers identified (which are summarized below) “provide a balanced view of organizational complexity from the code viewpoint.”
The researchers then used the technique of data splitting to test how well these organizational measures could predict “failure-proneness,” or the probability that a particular software element will fail in operation in the field. (The data splitting technique is exactly what it sounds like: the researchers took their dataset of over 3,000 modules exceeding 50 million lines of code, and divided it into random parts. Then they tested how accurate the predictions from their models were within each of the parts.)
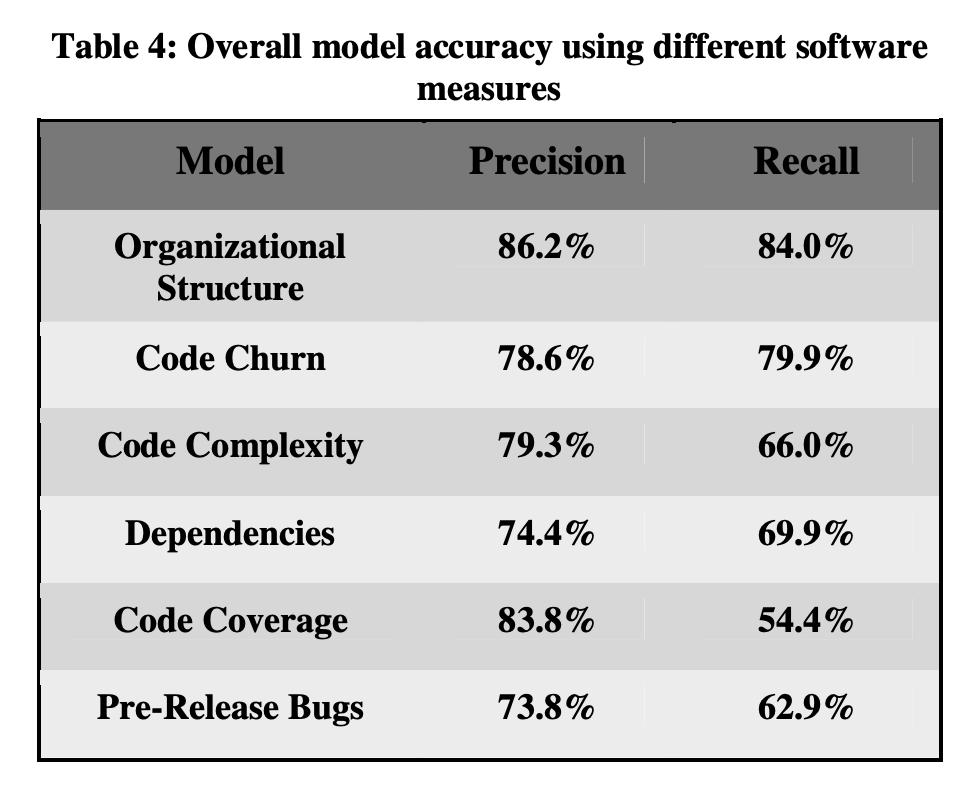
Two types of measures were used to test the accuracy of the prediction models: “precision” and “recall” measures. “Precision” asks the question, of the modules that the prediction thought had bugs, how many actually did have bugs? “Recall” asks, how many modules that had bugs did the prediction model detect?
Organizational structure is most predictive of software quality
The table below shows the precision and recall measures for each of the prediction models. We can see that organizational structure has the highest precision and the highest recall, meaning it is the better predictor of future problems with a codebase than other traditional metrics used before this study.
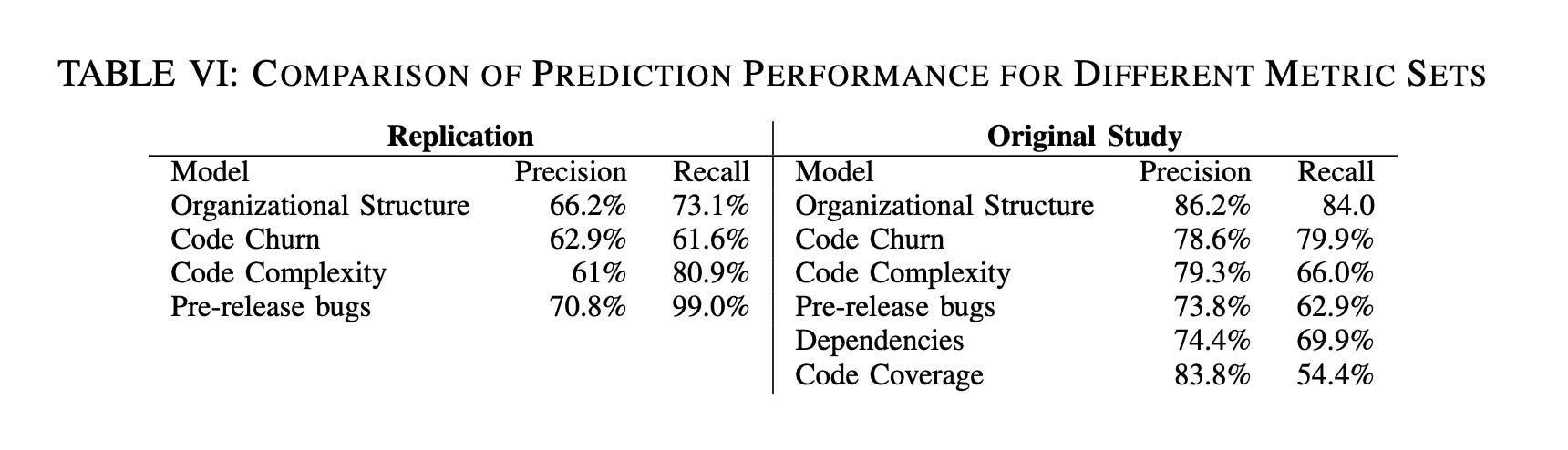
This study has since been replicated. Organizational complexity did not have as high of precision and recall measures in the replication study, however it was still found to be the best predictor of software quality.
Final thoughts
I find this study fascinating for a few reasons: first, the key finding says that the best predictor of software quality is not technical — it’s organizational complexity. It also uses metrics to measure organizational complexity that relate to code ownership, which on its own has been linked to software quality. Finally, it reminds of a Google-based study that found a casual link between software quality and developer productivity.
That’s it for this week! If this email was forwarded to you, subscribe here so you don’t miss any future posts:
Share your thoughts and feedback anytime by replying to this email.
-Abi
That Conway fellow, he really nailed it.
What are some solutions to lower organizational complexity? Are you doomed to have high complexity if you're a large enterprise?